Running-TensorflowLite-CodeLab-On-Windows-1
모바일 환경에서 딥러닝 모델 사용하기
텐서플로우를 사용하여 이미 트레인한 딥러닝 모델을 모바일 환경에서도 사용할 수 있도록, 즉 이미지 인식 등의 딥러닝 모델을 앱 개발에서 쉽게 사용할 수 있도록 텐서플로우에서는 텐서플로우 모바일 TFMobile과 텐서플로우 라이트 TFLite를 공개했습니다. 텐서플로우에서 제공하는 TF Lite와 TF Mobile의 사용법을 정리한 CodeLab이 2개 있습니다. Tensorflow For Poets, Tensorflow For Poets2. 리눅스 환경을 기준으로 만들어진 이 두가지 코드랩을 윈도우 환경에서 따라해보고 싶은 분들을 위해 작성해보았습니다.
TF Mobile과 TF Lite의 차이점?
텐서플로우 모바일은 라이트보다 훨씬 더 먼저 나온 버전이고 텐서플로우 라이트는 조금 더 경량 모델로, 2018년에 새로 공개된 것으로 현재 공개된 것은 개발자 프리뷰버전입니다.
텐서플로우 모바일과 라이트 공식 홈페이지에 따르면, TF Lite는 Mobile에 비해 바이너리가 더 작고 디펜던시도 적으며 퍼포먼스는 더 좋을 것이라고 합니다. 다만 텐서플로우 라이트는 현재 InceptionV3와 MobileNet 아키텍처만을 지원하고 있습니다.
파일 형식의 차이: 텐서플로우 모바일은 PC에서 텐서플로우를 통해 트레인한 모델의 graph.pb파일과 레이블 텍스트파일을 그대로 앱에서 불러와서 사용합니다. 텐서플로우 라이트는 트레인된 그래프 파일(pb형식)과 레이블을 TOCO(Tensorflow lite용 컨버터)를 이용하여 tflite라는 형식의 파일로 변환한 후에 그 lite파일을 모바일 앱에서 사용합니다.
그런데 2018년 5월 현재 기준 TOCO의 윈도우 지원이 돼지 않는다고 텐서플로우팀에서 밝혔습니다. 참고
따라서 윈도우 환경에서 개발해야하는 경우, 코드랩2의 변환 과정은 생략하고 grpah.pb파일 그대로 TFMobile 앱으로 사용하거나 그 파일 변환 부분만 리눅스 환경에서 따로 진행해야합니다.
: 코드랩에 들어가기 전에.
Transfer Learning 과 Retrain
CNN 모델의 일종인 모바일넷, 인셉션 등의 딥러닝 모델을 이미지 인식을 위해 처음부터 끝까지 트레이닝 시키기 위해서는 일반 컴퓨터가 감당하기에는 아주 많은 시간과 자원이 듭니다. 따라서 코드 랩에서는 누구나 쉽게 따라해 볼 수 있도록 하기 위해, 이미 ImageNet 데이터셋으로 fully trained된 모델의 최상위 레이어만 사용자가 원하는 데이터셋으로 retrain하는 단계를 거치고 있습니다.
pre-trained된 전체 네트워크의 하위레이어는 class-object specific하지 않을 것이라는 가정 하에, 이미지넷의 1000여개 사물, 동물 클래스에 대한 이미지를 가지고 트레인된 모델을 사용해서 최상위 레이어만 re-train하는 것을 Transfer Learning이라고 합니다.(트랜스퍼러닝에는 최상위 레이어만 리트레인하는 것 외에 상위 레이어를 fine-tuning하는 등 여러가지 방법이 있지만 현재 코드랩에서 다루고 있는 부분까지만 설명하겠습니다.)
즉 트랜스퍼 러닝은 성능이 입증된 fully pre-trained CNN을 가져다가 feature를 추출하는 데에 사용하고, 이를 바탕으로 우리가 원하는 분류(커스텀 데이터셋)를 수행하도록 만드는 것이라고 볼 수 있습니다.
이러한 트랜스퍼 러닝의 장점은
- 적은 데이터셋(클래스당 1000개 미만)으로도 오버피팅을 피하며 효율적 트레이닝 가능하다는 점. 라벨링 된 양질의 데이터를 충분히 모으는 것이 쉽지 않은데, 수백개 정도의 데이터로도 충분히 높은 퍼포먼스를 보입니다.
- 속도 및 비용 현격하게 절약. 이미지넷과 같은 딥러닝용 대규모 데이터로 CNN전체 모델을 학습시킬 때 컴퓨터 사양에 따라 며칠, 몇 달이 걸리지 모르는 것와 비교하여 최상위 레이어만 리트레인할 경우 수 분내에 리트레이닝 과정이 끝나는 것을 코드랩을 통해 확인할 수 있을 것입니다.
밑에서 진행하게 될 코드랩은 이미지넷 데이터셋으로 1000개의 사물, 동물 클래스에 대해 트레이닝 된 모델을 가져다가 daisy, dandelion, rose 등 다섯가지 종류의 꽃 이미지를 가지고 retrain하여 그 다섯가지 꽃 종류를 분류하는 모델을 만들어 그것을 모바일에서 사용하는 과정입니다.
코드랩을 시작하기 전에 컴퓨터에 python, git 및 tensorflow1.7 버전은 이미 설치된 상태여야합니다.
단계 1. 준비 단계
윈도우 커맨드창(명령프롬프트)를 열고 원하는 디렉토리에 tensorlfow-for-poets-2 파일들을 내려받은 후 그 폴더로 들어갑니다.
git clone https://github.com/googlecodelabs/tensorflow-for-poets-2
cd tensorflow-for-poets-2
저는 다운로드 폴더에서 진행하였습니다. 이렇게 다운로드 폴더에 코드랩 파일들이 다운받아진 것을 확인해볼 수 있습니다.

그 다음이 리트레인을 하기 위한 이미지셋으로 쓸 꽃 사진들을 다운받습니다. 리눅스 환경에서는 curl을 사용하여 커맨드창에서 바로 받아서 원하는 위치에 압축까지 해제할 수 있지만, 윈도우에서는 인터넷 주소창에 아래 주소를 복사해넣으면 파일을 다운받는 방법을 씁시다.
아래 주소를 브라우저 주소창에 써서 다운을 받으세요.
http://download.tensorflow.org/example_images/flower_photos.tgz
flower_phohtos.tgz 파일이 다운 받아지면, 현재 작업하고 있는 폴더인 tensorflow-for-poets-2 내부의 tf_files 폴더에 압축을 풀어주세요.
비어있던 tf_files폴더에 flower_photos라는 폴더 아래 각 꽃 종류별 이미지 데이터셋이 저장된 것을 확인해주세요.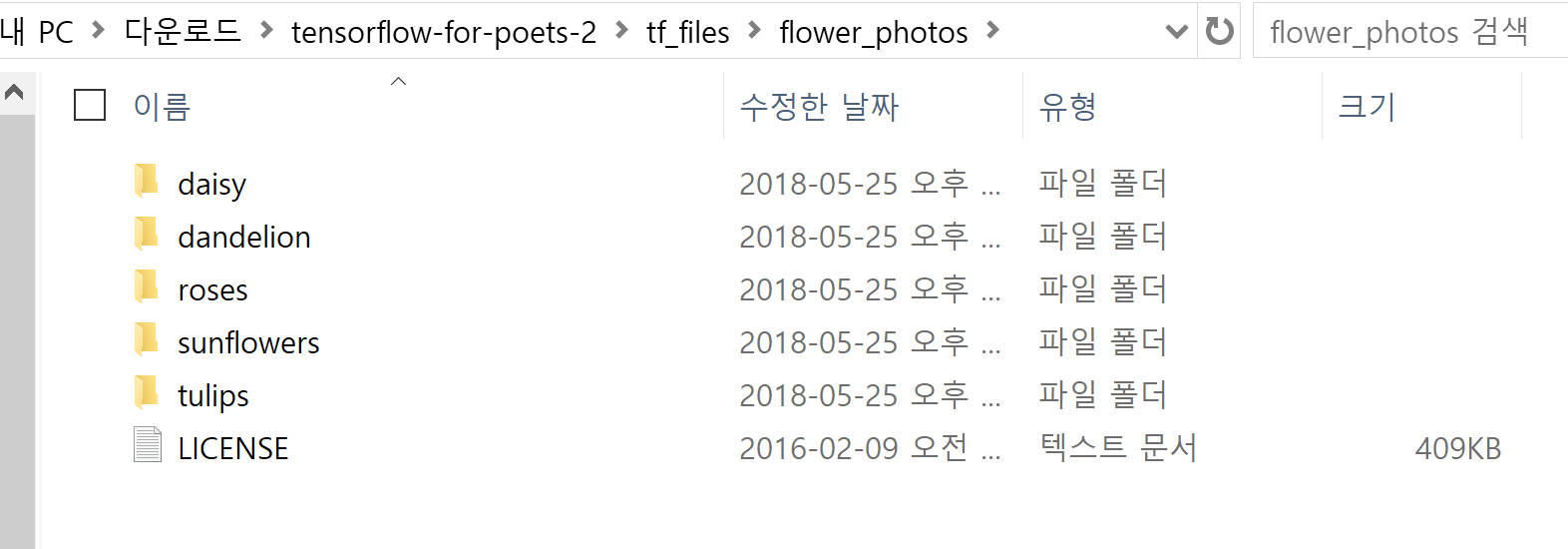
cd tf_files/flower_photos
dir
위와 같이 커맨드창에서 바로 확인해볼 수도 있습니다.
단계 2. 네트워크 리트레이닝 하기
본 코드랩에서는 “모바일넷”이라는 아키텍처를 사용하는데, 이것은 모바일에서 이용하기 좋도록 CNN을 좀 더 가볍게 만든 구조입니다. 모바일넷의 구조에 대한 설명은 여기에서 자세히 확인할 수 있습니다.
모바일넷에서 조정할 수 있는 부분은
- 인풋 이미지 해상도: 128,160,192,224px 중 선택 가능. 당연히 더 높은 해상도의 인풋을 사용하면 프로세싱 시간은 더 길지만 결과적으로 분류정확도는 높다.
- 가장 큰 모바일넷에 비교한 상대적 모델 사이즈 : 1.0, 0.75, 0.50, 0.25 중 선택 가능.
코드랩에서는 224, 0.25 세팅을 사용합니다.
이 설정을 리눅스 환경에서는 shell variable로
IMAGE_SIZE=224
ARCHITECTURE="mobilenet_0.50_${IMAGE_SIZE}"
이렇게 설정해주고 이후에 리트레인을 실행할 때에 IMAGE_SIZE와 ARCHITECUTRE를 저렇게 설정한대로 불러와서 실행하게 되는데, 윈도우에서는 그냥 리트레인 실행 시에 직접 대입해서 사용하면 됩니다. 즉 아무것도 하지 않고 넘어가면 됩니다.
텐서보드 먼저 실행시키기
리트레인을 시작하기 전에, 텐서보드를 먼저 실행시켜 둡니다. (텐서보드는 트레이닝 과정과 내역을 시각화하여 보여주는 보조 툴로, 설치에 실패한다면 지금은 꼭 안해도 코드랩 진행에는 문제가 안 됩니다.)
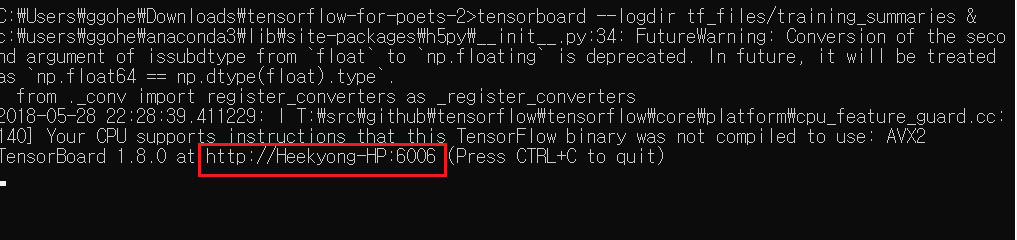
tensorboard --logdir tf_files/training_summaries &
텐서보드를 성공적으로 실행시켰을 경우 다음과 같은 메시지가 뜨고, 표시된 주소로 접속하면 텐서보드를 확인할 수 있습니다.
이제 본격적으로 리트레인을 진행합니다. 커맨드 창에서 tensorflow-for-poets-2 디렉토리 내에서 다음 명령을 실행시키세요.
python -m scripts.retrain -h
리트레인 파일을 실행시키기 전에 먼저 어떤 arguement 들이 있는지 등을 한번 확인해봅시다.
이제 리트레인 파일을 다음과 같은 설정으로 실행시켜 보겠습니다.
python -m scripts.retrain --bottleneck_dir=tf_files/bottlenecks --how_many_training_steps=500 --model_dir=tf_files/models/ --summaries_dir=tf_files/training_summaries/"mobilenet_0.50_224" --output_graph=tf_files/retrained_graph.pb --output_labels=tf_files/retrained_labels.txt --architecture="mobilenet_0.50_224" --image_dir=tf_files/flower_photos
윈도우 환경에서는 shell variable 설정없이 그냥 매뉴얼하게 이 코드의 summaries_dir 행과 architecture행을 “mobilenet_0.50_224”로 직접 채워 설정했습니다.
위에서 configuration 옵션을 기억하시나요? 아키텍처 필드를 보면 mobilenet_0.50_224라고 돼있는데, 앞에서 말했듯 0.50을 1.0이나 0.75 등 주어진 옵션의 다른 숫자로 바꿀 수 있습니다. 인풋 이미지사이즈에 해당하는 224 역시 128 등 다른 옵션으로 바꿔볼 수 있습니다.
how_many_training_steps같은 경우 트레이닝 iteration을 몇번 돌 것인지인데요, 여기서 디폴트가 500번이지만 원하는대로 변경해보면서 이후에 결과를 비교해 볼 수 있습니다. 또 summaries_dir 디렉토리 지정은 텐서보드를 위해 트레이닝 서머리를 이쪽으로 보내라는 지정입니다.
좀 더 살펴보자면, 보시는대로 트레인된 결과로 output 그래프는 retrained_graph.pb라는 파일로 나오게되고, output 레이블은 retrained_labels.txt로 나옵니다. 인풋 이미지들은 image_dir에 지정된 경로에서 가져오게 돼있습니다. –learning_rate 플래그는 여기서 따로 설정하고 있지 않아서 디폴트인 0.01대로 갑니다만 이 역시 조정 가능합니다. –learning_rate=0.005이런 식으로 arguement를 추가하면 됩니다. 알고 계시는대로 러닝레이트가 커질 수록 트레이닝은 금방 끝나지만 precision이 떨어질 수 있고, 러닝레이트가 작을 수록 트레이닝에 시간이 오래 걸리지만 precision이 높아질 수 있습니다.
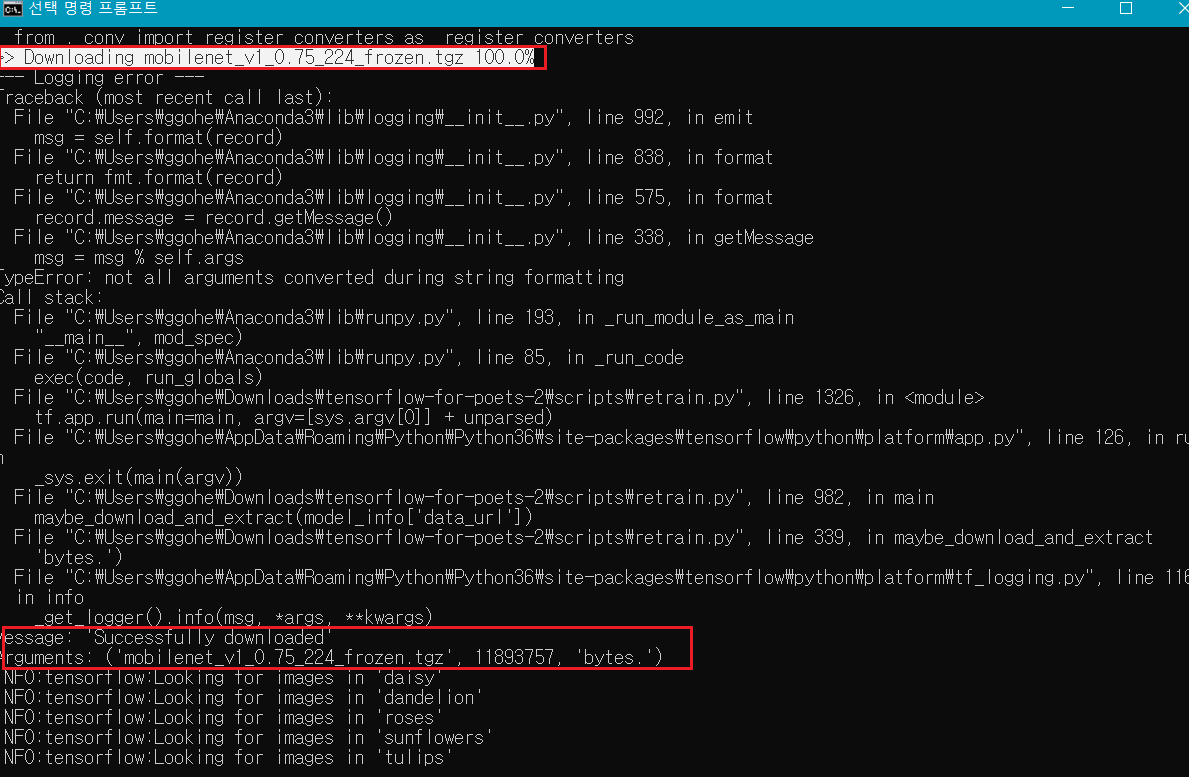
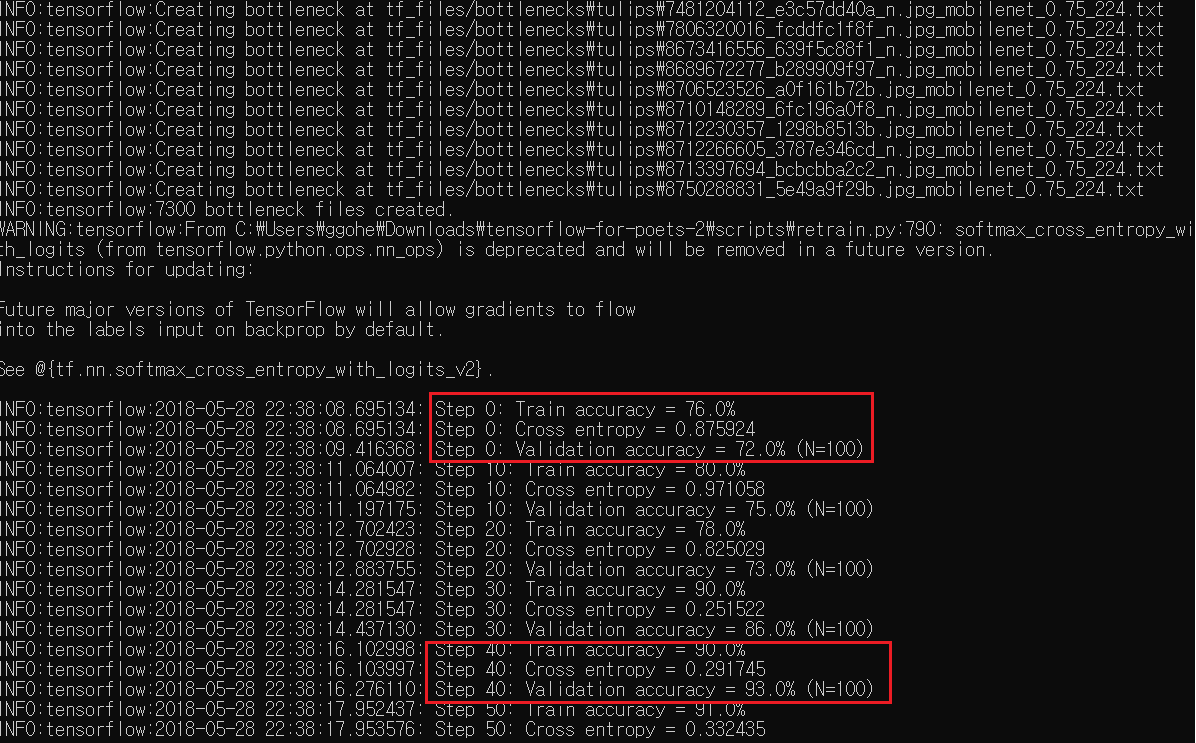
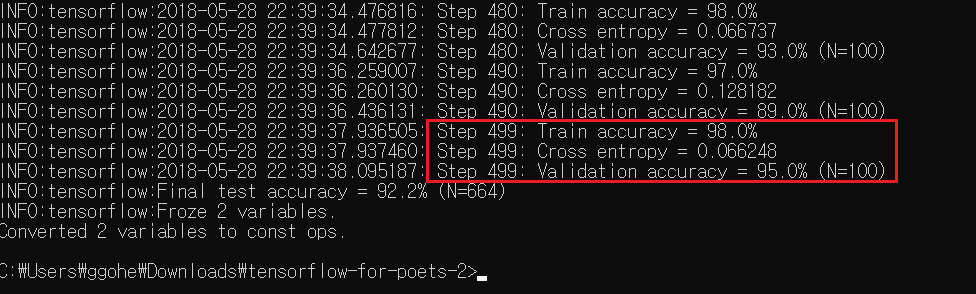
실행을 시키면 커맨드창에서 위와 같은 진행 내역을 실시간으로 확인할 수 있습니다. 우선 모바일넷 아키텍처 모델을 불러오고, 그리고 각 모든 인풋 이미지(꽃사진들) 파일에 대한 보틀넥을 만들고, 트레이닝 스텝 수 만큼 트레이닝을 반복하는 모습을 지켜볼 수 있습니다. 트레이닝을 여러번 반복시킬 수록 점점 accuracy가 높아지는 것을 확인할 수 있죠? 과정이 모두 끝나고 나면 텐서보드에서 그 내역을 시각화해서 확인해볼 수 있습니다.
retrain의 아웃풋으로 retrained_graph.pb파일과 레이블 파일이 생긴 것을 확인해볼 수 있습니다.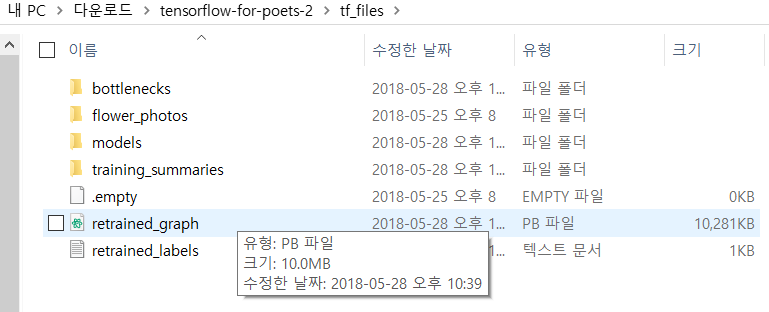
단계 3. 텐서보드로 트레이닝 내역 확인하기
저는 아키텍처를 모바일넷_0.50_224와 0.75_224로 두 번 실행시켜봤는데요. 간단히 말해서 accuracy는 높을 수록, 크로스 엔트로피는 낮을 수록 좋은 것입니다. 트레이닝 셋에 대한 오버피팅을 방지하기 위해 따로 validation set에 대한 결과도 보여주고 있습니다.
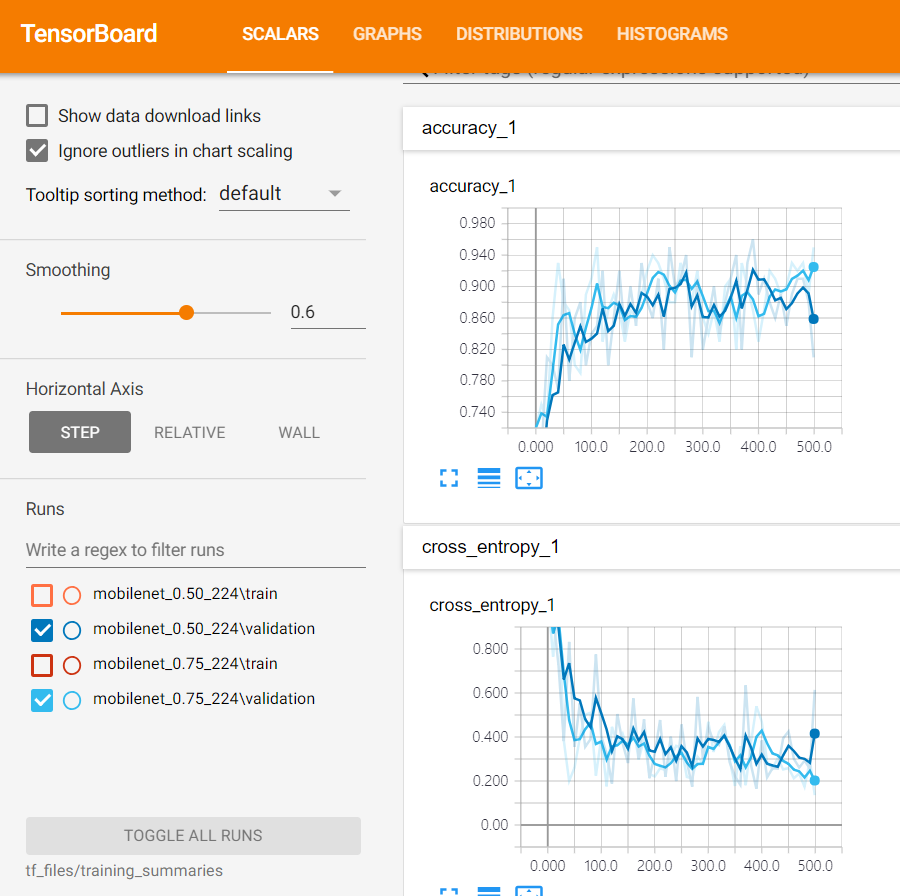
우선 0.50_224에 대해 트레이닝 횟수를 거치며 accuracy가 어떻게 올라갔는지를 이렇게 확인해볼 수 있습니다.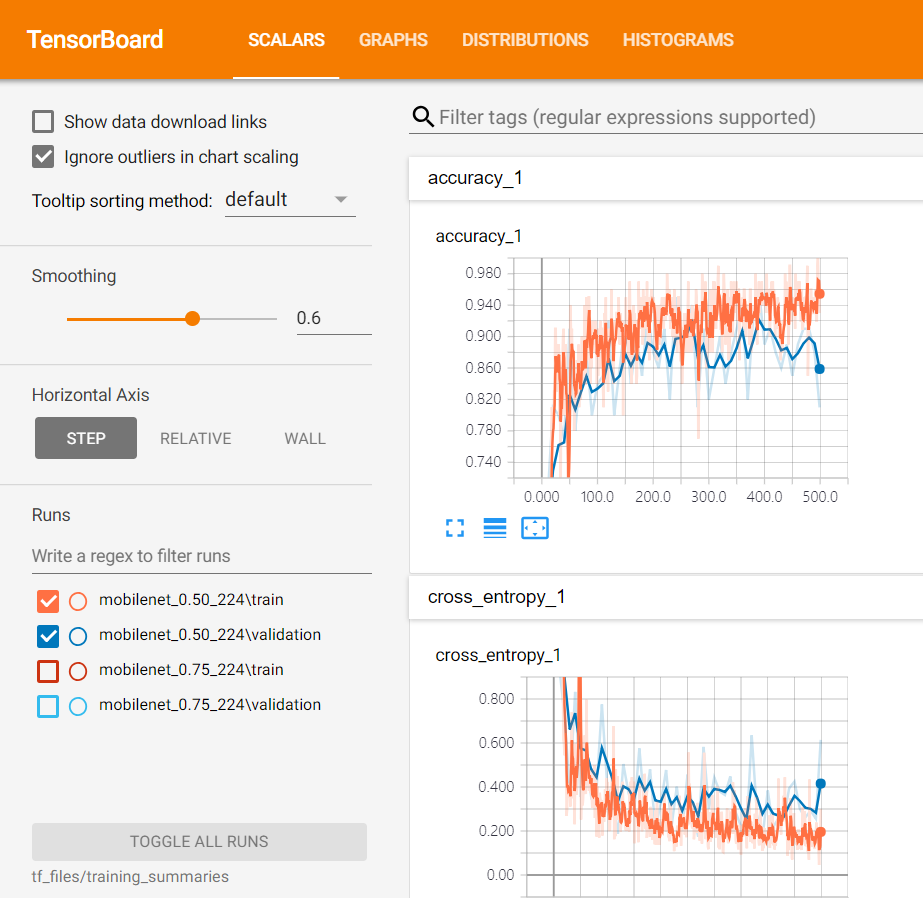
0.75_224에 대해서도 마찬가지입니다.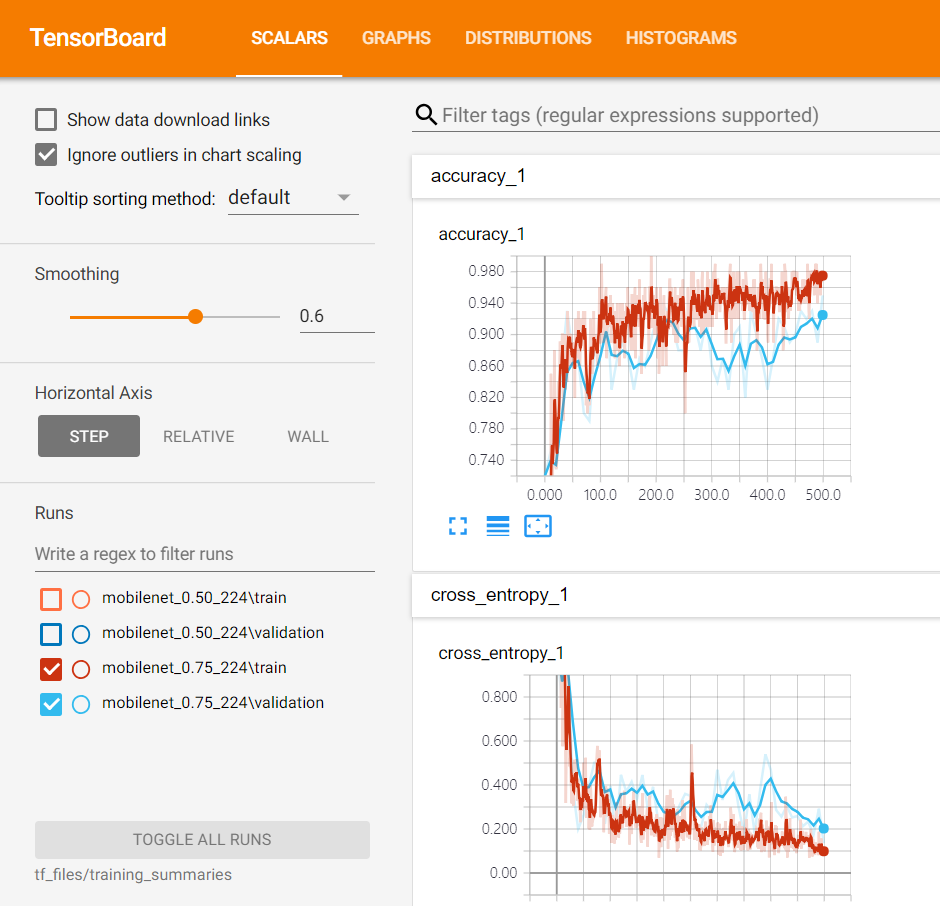
0.50모델이 0.75모델보다 모바일넷 규모자체가 큰 거였죠? 두개를 사용했을 때 어떤 차이가 있는지도 비교해봅시다.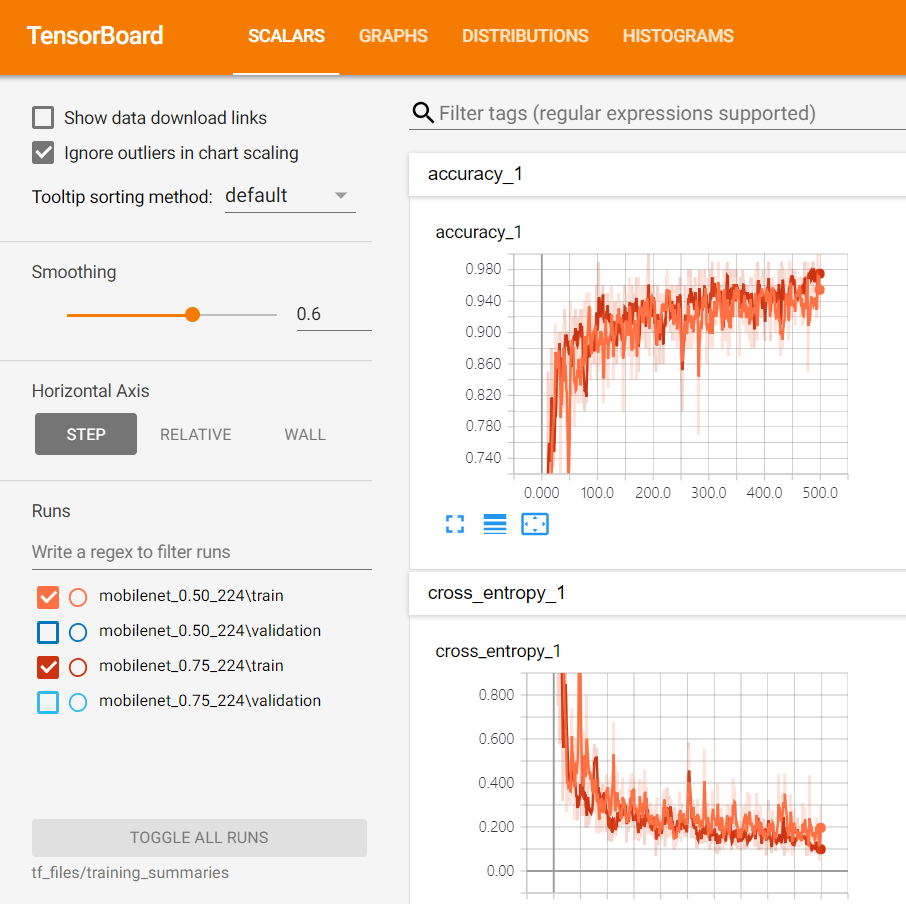
추가적으로, 그래프 탭에 가보면 복잡한 구조에 대해서 자세히 뜯어볼 수 있습니다.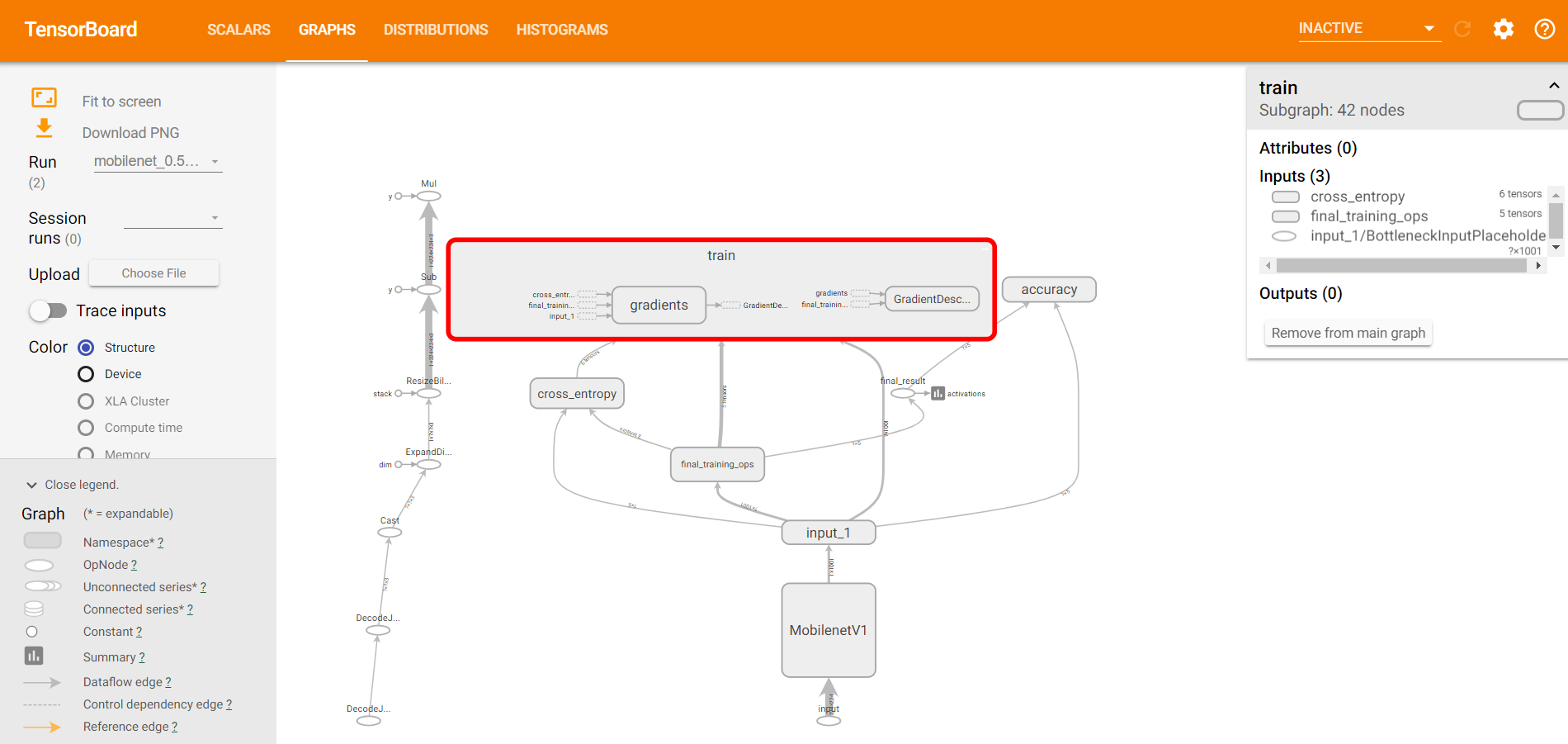 그래프의 부분을 클릭하면 상세 하부 구조가 다 나오기 때문에 자세히 들여다보면 코드를 이해하는 데에도 도움이 됩니다.
그래프의 부분을 클릭하면 상세 하부 구조가 다 나오기 때문에 자세히 들여다보면 코드를 이해하는 데에도 도움이 됩니다.
단계4. 리트레인 된 모델 실행해보기
여태까지 이미지넷에 트레이닝된 모델을 꽃 이미지들을 가지고 retrain 시켜서 다섯가지 꽃을 분류하는 모델로 만들었습니다. 이제 리트레인된 모델을 이용하여 분류가 실제로 잘 되는지 확인을 해보겠습니다.
python -m scripts.label_image -h
스크립트 폴더에 있는 레이블_이미지라는 파이썬 파일을 이용해 확인 해볼 수 있는데요, -h(help)를 통해 어떤 파라미터가 있는지를 확인해봅니다.
그럼 인풋파일 중 데이지 이미지 중 하나인 21652746_cc379e0eea_m.jpg로 시험해보겠습니다.
python -m scripts.label_image --graph=tf_files/retrained_graph.pb --image=tf_files/flower_photos/daisy/21652746_cc379e0eea_m.jpg
실행시킨 결과 daisy일 확률이 94퍼센트정도로 나오는 것을 아래와 같이 확인할 수 있습니다.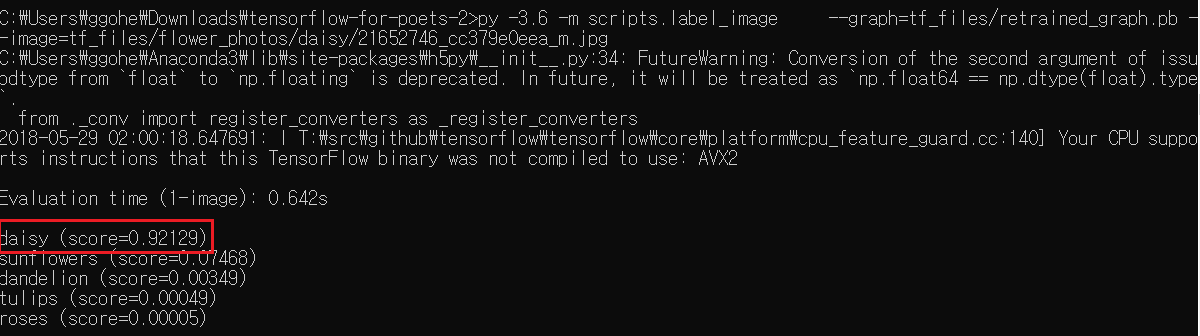
image_label파일을 실행시키면서 –image 부분 arguement에 경로와 파일을 지정해주면 다른 어떤 이미지 파일도 이 모델로 분류시킬 수 있습니다. 트레이닝셋에 없었던 파일이여도 괜찮습니다. 다만 주의할 점은 앞서 리트레이닝 시에 이미지 인풋사이즈를 225보다 작은 설정으로 했던 경우, –input_size 플래그를 통해 별도로 같은 인풋사이즈로 지정해주어야 합니다.
여기까지가 트랜스퍼 러닝을 사용해 fully trained된 모바일넷 모델을 작은 커스텀 데이터셋으로 retrain시키는 과정이었습니다. 본 과정은 예제로 주어진 꽃 데이터가 아니라, 본인이 직접 고른 이미지 셋으로도 쉽게 적용해볼 수 있습니다. 저도 직접 크롤링한 이미지로 해봤는데 클래스당 500여개의 이미지로도 잘 인식이 되는 것을 확인했습니다. 다만 기존 pre-train에 사용된 이미지넷 데이터가 사물, 동물 인식용이기 때문에, 완전히 다른 성질의 이미지일 경우 성능이 어떻게 나올 지는 잘 모르겠습니다.
이 코드랩에서 나온 retrained_graph.pb파일과 레이블 파일을 이용해 모바일 어플리케이션에서 사물인식 딥러닝 모델을 쓸 수 있는데 이는 별개의 코드랩이므로 다음 포스트에서 작성하도록 하겠습니다. 위에서 말씀드린대로 TF Mobile에서는 그래프파일과 레이블 파일을 그대로 가지고 쓰도록 설계돼있고 TF Lite는 그래프를 tflite라는 형식으로 변환하는 과정을 거쳐 변환된 tflite 형식의 파일을 사용하도록 돼있습니다. 그리고 2018년 5월 현재 윈도우 환경에서는 TOCO(컨버터) 지원이 되지 않아 변환이 불가능합니다.